We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
General description of the gene and the encoded protein(s) using information from HGNC and Ensembl, as well as predictions made by the Human Protein Atlas project.
Gene namei
Official gene symbol, which is typically a short form of the gene name, according to HGNC.
Cancer-related genes Disease related genes RAS pathway related proteins Transcription factors
Predicted locationi
All transcripts of all genes have been analyzed regarding the location(s) of corresponding protein based on prediction methods for signal peptides and transmembrane regions.
Genes with at least one transcript predicted to encode a secreted protein, according to prediction methods or to UniProt location data, have been further annotated and classified with the aim to determine if the corresponding protein(s) are secreted or actually retained in intracellular locations or membrane-attached.
Remaining genes, with no transcript predicted to encode a secreted protein, will be assigned the prediction-based location(s).
The annotated location overrules the predicted location, so that a gene encoding a predicted secreted protein that has been annotated as intracellular will have intracellular as the final location.
Gene information from Ensembl and Entrez, as well as links to available gene identifiers are displayed here. Information was retrieved from Ensembl if not indicated otherwise.
Chromosome
X
Cytoband
q13.1
Chromosome location (bp)
71095851 - 71103532
Number of transcriptsi
Number of protein-coding transcripts from the gene as defined by Ensembl.
The Structure section provides predicted structures from the Alphafold protein structure database and available experimental structures from Protein Data Bank (PDB).
In the Structure drop-down menu all experimental structures from PDB are available for selection and display. The structures are displayed using the NGL Viewer and can be zoomed-in and rotated either manually or by checking the Autorotate box. The Color scheme can be selected to show the residue index, chain name or confidence score (as B-factors and pLDDT score for experimental and predicted structures, respectively). The positions for available antigen sequences in the structure are shown if Antigens is turned to ON, and the Variants slider can be used to show the positions of clinical and population variants.https://github.com/nglviewer/ngl
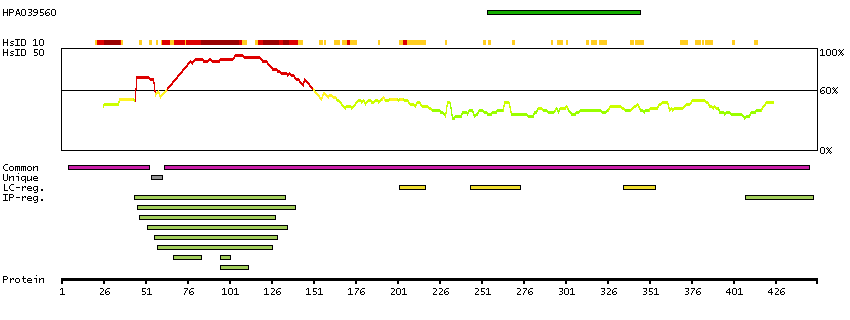
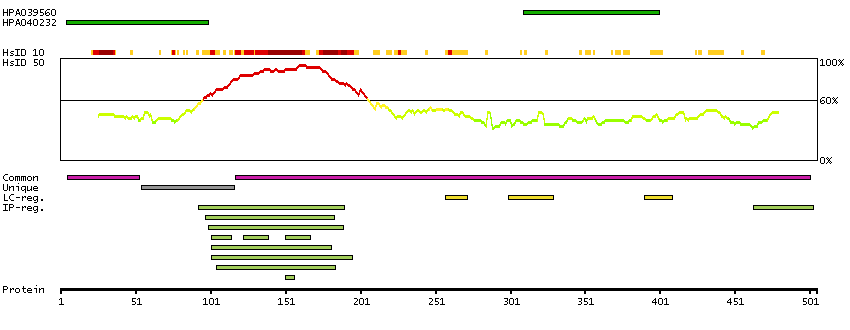
The protein browser displays the antigen location on the target protein(s) and the features of the target protein. The tabs at the top of the protein view section can be used to switch between the different splice variants to which an antigen has been mapped.
At the top of the view, the position of the antigen (identified by the corresponding HPA identifier) is shown as a green bar. A yellow triangle on the bar indicates a <100% sequence identity to the protein target.
Below the antigens, the maximum percent sequence identity of the protein to all other proteins from other human genes is displayed, using a sliding window of 10 aa residues (HsID 10) or 50 aa residues (HsID 50). The region with the lowest possible identity is always selected for antigen design, with a maximum identity of 60% allowed for designing a single-target antigen (read more).
The curve in blue displays the predicted antigenicity i.e. the tendency for different regions of the protein to generate an immune response, with peak regions being predicted to be more antigenic.The curve shows average values based on a sliding window approach using an in-house propensity scale. (read more).
If a signal peptide is predicted by a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius (turquoise) and/or transmembrane regions (orange) are predicted by MDM, these are displayed.
Low complexity regions are shown in yellow and InterPro regions in green. Common (purple) and unique (grey) regions between different splice variants of the gene are also displayed (read more), and at the bottom of the protein view is the protein scale.
FOXO4-201
FOXO4-202
PROTEIN INFORMATIONi
The protein information section displays alternative protein-coding transcripts (splice variants) encoded by this gene according to the Ensembl database.
The ENSP identifier links to the Ensembl website protein summary, while the ENST identifier links to the Ensembl website transcript summary for the selected splice variant. The data in the UniProt column can be expanded to show links to all matching UniProt identifiers for this protein.
The protein classes assigned to this protein are shown if expanding the data in the protein class column. Parent protein classes are in bold font and subclasses are listed under the parent class.
The Gene Ontology terms assigned to this protein are listed if expanding the Gene ontology column. The length of the protein (amino acid residues according to Ensembl), molecular mass (kDalton), predicted signal peptide (according to a majority of the signal peptide predictors SPOCTOPUS, SignalP 4.0, and Phobius) and the number of predicted transmembrane region(s) (according to MDM) are also reported.
Predicted intracellular proteins Intracellular proteins predicted by MDM and MDSEC Transcription factors Helix-turn-helix domains RAS pathway related proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Translocations Disease related genes Mapped to neXtProt neXtProt - Evidence at protein level Protein evidence (Kim et al 2014)
Show all
GO:0000785 [chromatin] GO:0000978 [RNA polymerase II cis-regulatory region sequence-specific DNA binding] GO:0000981 [DNA-binding transcription factor activity, RNA polymerase II-specific] GO:0001228 [DNA-binding transcription activator activity, RNA polymerase II-specific] GO:0003677 [DNA binding] GO:0003700 [DNA-binding transcription factor activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0006355 [regulation of transcription, DNA-templated] GO:0006357 [regulation of transcription by RNA polymerase II] GO:0007049 [cell cycle] GO:0007050 [cell cycle arrest] GO:0007275 [multicellular organism development] GO:0007517 [muscle organ development] GO:0008013 [beta-catenin binding] GO:0008134 [transcription factor binding] GO:0008285 [negative regulation of cell population proliferation] GO:0008286 [insulin receptor signaling pathway] GO:0016525 [negative regulation of angiogenesis] GO:0016579 [protein deubiquitination] GO:0016607 [nuclear speck] GO:0019899 [enzyme binding] GO:0030154 [cell differentiation] GO:0042802 [identical protein binding] GO:0043565 [sequence-specific DNA binding] GO:0045944 [positive regulation of transcription by RNA polymerase II] GO:0048863 [stem cell differentiation] GO:0051151 [negative regulation of smooth muscle cell differentiation] GO:0070317 [negative regulation of G0 to G1 transition] GO:0071158 [positive regulation of cell cycle arrest] GO:1990837 [sequence-specific double-stranded DNA binding]
Predicted intracellular proteins Intracellular proteins predicted by MDM and MDSEC Transcription factors Helix-turn-helix domains RAS pathway related proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Translocations Disease related genes Mapped to neXtProt neXtProt - Evidence at protein level Protein evidence (Kim et al 2014)
Show all
GO:0000785 [chromatin] GO:0000978 [RNA polymerase II cis-regulatory region sequence-specific DNA binding] GO:0000981 [DNA-binding transcription factor activity, RNA polymerase II-specific] GO:0001228 [DNA-binding transcription activator activity, RNA polymerase II-specific] GO:0003677 [DNA binding] GO:0003700 [DNA-binding transcription factor activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0006355 [regulation of transcription, DNA-templated] GO:0006357 [regulation of transcription by RNA polymerase II] GO:0007049 [cell cycle] GO:0007050 [cell cycle arrest] GO:0007095 [mitotic G2 DNA damage checkpoint] GO:0007275 [multicellular organism development] GO:0007517 [muscle organ development] GO:0007568 [aging] GO:0008013 [beta-catenin binding] GO:0008134 [transcription factor binding] GO:0008285 [negative regulation of cell population proliferation] GO:0008286 [insulin receptor signaling pathway] GO:0014911 [positive regulation of smooth muscle cell migration] GO:0016525 [negative regulation of angiogenesis] GO:0016579 [protein deubiquitination] GO:0016607 [nuclear speck] GO:0019899 [enzyme binding] GO:0030154 [cell differentiation] GO:0031667 [response to nutrient levels] GO:0042802 [identical protein binding] GO:0043565 [sequence-specific DNA binding] GO:0045893 [positive regulation of transcription, DNA-templated] GO:0045944 [positive regulation of transcription by RNA polymerase II] GO:0048863 [stem cell differentiation] GO:0051151 [negative regulation of smooth muscle cell differentiation] GO:0070317 [negative regulation of G0 to G1 transition] GO:0071158 [positive regulation of cell cycle arrest] GO:1990785 [response to water-immersion restraint stress] GO:1990837 [sequence-specific double-stranded DNA binding] GO:1990841 [promoter-specific chromatin binding]


 The Human Protein Atlas project is funded
The Human Protein Atlas project is funded